2 月很有意思。反思
一、潮A持续DeepSeek 反思潮
在 DeepSeek 的既被集体反思潮中,无论是重新大厂内部的“AGI 创业团队”、还是审视 AGI 的明星创业公司,都进行了战略调整。又被很显然,低估DeepSeek 的反思暴击让整个行业都进行了一次深刻的反思,值得注意的潮A持续几个变化是:
首先,大模型创业公司重新将工艺突破提升到一个新的既被高度、超越产物更新成为公司战略增长的重新优先级。
据近日与张予彤接触过的审视 VC 反馈,DeepSeek 不花一分钱投流的又被崛起启示了 AGI 的工艺高度,也让 Moonshot 反思了过去一年类互联网打法、低估过度重视产物投流的反思策略局限性。在未来的一年,Moonshot 要将基础模型的突破作为重点,将更多资源投到工艺而非研发上。
事实上,这不仅仅是月之暗面的结论,也是这波 AGI 创业潮中卡工艺生态位的大模型公司的普遍转变。与此相对应的,是产物团队的资源比重下降,因为 DeepSeek 的成功已经侧面证明了:AGI 时代可能不需要产物经理,也不需要投流,只要工艺实力提升后就会有客户增长。
2024 年的投流大战,以 DeepSeek 不花一分钱、DAU 最高时达 4000 万落下帷幕,而受创最重的自然是投流团队,因为钱相当于白花了。投流越多、伤害越大,如 Moonshot;投流越少,伤害越小,如 MiniMax。
据 AI 科技评论获悉,MiniMax 前产物一号位离职的原因之一,就是曾与创始人在投流上发生分歧。MiniMax 的组织架构之前是互联网打法,按照不同产物进行分组,产物团队一度达到 200 人,但 2024 年年中开始就一直在调整产物团队,接下来可能会进一步裁减产物人员。雷峰网
其次,是字节与腾讯的攻守异位,以及字节大模型工艺团队的架构调整。
过去一周,腾讯元宝接入 DeepSeek 后在中国区苹果免费 APP 下载排行榜上超过豆包,排名第二、仅次于 DeepSeek。在“DeepSeek+”的风潮下,相比百度、阿里、字节等有工艺包袱的大厂来说,腾讯的元宝与微信等应用迅速抓住了机会,毫无负担地接入了 DeepSeek,一下子由过去两年的被动防守转为主动出击,变守为攻,扭转了局势。
业内周知,在过去的两年,腾讯在大模型、AIGC 相关工艺与产物上虽然努力追赶,但始终不温不火。又由于将算力与人才等资源更多投入基础模型,文生影片等方向的研究资源被作用,团队核心骨干从腾讯流向快手、字节等团队。可以说,DeepSeek 救了腾讯大模型一把。
也因此,有业内人士认为:基础模型的研究最终只需要 DeepSeek 一家即可。随之引发的,是近日传出的大模型公司有老股东开始张罗退股的声音,认为“智谱、阶跃甚至字节、阿里等公司的大模型都没戏了”。——对于这种声音,笔者不敢苟同,认为应该持续观望。
有一个比喻能很好地形容当前中国大模型创业潮的格局:
一个富二代学霸做了一份接近满分的卷子,并把答案公布了出来。但这份答案的学习有一定的资源成本与面子成本,另一个能承担起这两种成本的富二代学渣直接拿来抄了、也考了接近满分的成绩。现在留下一群从农村通过赞助入学、平时考七八十分的学生,以及同是富二代但努力方向错了的学生,不知所措。
他们终将认识到,开放社会的竞争不一定公平,但一定残酷。打破这种结构性困境很难,或许需要“一命二运三风水四积阴德五读书”,但他们没有其他选择。
回到现实,字节的大模型团队进行调整,也是因为 AGI 的竞争格局发生了变化——DeepSeek 冲出来之前,业内几乎所有人都在夸字节的豆包,豆包也上升十分迅猛,给 kimi 造成极大的围剿;但 DeepSeek 霸屏整个春节后,字节意识到,AGI 仍是一个高度的果实,必须换一个更能打的将领。
据 AI 科技评论验证,此前字节的基础模型工艺研究由朱文佳带领,春节后进行了一次大的人员调整,基础模型工艺研发的一号位换成了由吴永辉,黄文灏等在 2024 年新加入的大模型骨干都向吴永辉汇报,而朱文佳则转向了模型应用一号位,吴永辉与朱文佳都向梁汝波汇报。
经 AI 科技评论梳理,2023 年字节刚组建大模型团队时,团队人员主要来自字节内部,包括搜索、抖音、西瓜、TikTok 等等多条知名业务线,在字节过往产物上有过大大小小的胜仗,朱文佳下面各个小组中一号位人选从外面招入的人才并不多。
从 2024 年年中开始,越来越多 AGI 方向的知名人才被招入字节,团队开始换血。据知情人士分析,这背后的原因是:朱文佳等人来自搜推广工艺背景,而大模型是新的范式,两者不一定适合。字节、MiniMax 等公司此前低估 RL 工艺路线就是一个例证。吴永辉代替朱文佳成为基础模型研究一号位,意味着字节换血的决心更彻底。雷峰网
吴永辉此前在谷歌的职级仅次于 Jeff Dean,是谷歌 Gemini 的核心贡献者之一。而据几位硅谷华人的信源,吴永辉擅长模型工程。谷歌自 2017 年发布 Transformer 后一直在大模型赛道上持续创新,且谷歌研究大模型一直是从底层框架、算力到上层运算规则的系统性推进,从知识面上吴永辉确更适合大模型工艺一号位的角色。(谷歌 Gemini 是否被低估?欢迎感兴趣的读者添加作者微信 Fiona190913 交流)
据知情人士透露,朱文佳此前在带领字节大模型工艺研发时,在人才任用上更重用以往一起打过仗的亲信乔木等人,同时在大模型基础研究的创新 idea 采用上不够开放。这背后的逻辑不难理解:AGI 的工艺有极高不确定性、用熟悉的队友能减少沟通成本。如果 AGI 是一个很低的桃子,“钱多人傻”的打法也许可以,但事实或许并非如此。
据了解,新加入字节的工艺人员曾向朱文佳提过诸如 SPPO 等强化学习方向、火星优化器等高效训练方向的工艺方案,“一些方案明明自己验证了 work、但被朱文佳移交给身边的人验证后被反馈不 work 而弃掉”。此前字节内部赛马文生影片,其他团队赛赢,但后续成果被朱文佳划到了 Seed 团队。(更多字节大模型内部的研究细节,欢迎天街作者微信 Fiona190913 交流)
大模型是一项有门槛的创新工艺,无论在大厂还是创业公司,实际上都需要创业者的心态。第一批低估 AGI 的人已经被摁倒,但并非所有人都吸取了教训。雷峰网(公众号:雷峰网)
二、AGI 的壁垒在哪?
“运算规则是没有壁垒的。”一位大模型 VC 这样评论道。与此同时,还有相似的声音:“DeepSeek 现象只是昙花一现,过 6 个月就会被追上”,以及“大模型创业公司必然会死,最后赢家只有 DeepSeek 与大厂,你看腾讯元宝”。
笔者认为,在下论断之前,首先要回答一个问题:DeepSeek 已经实现终极 AGI 了吗?答案显然是否定的,即使是 DeepSeek 官方都承认,R1 模型仍有一些致命缺陷,比如通用能力不足、语言混淆、提示词敏感以及软件工程能力不足。
如果这个问题达成了共识,那么我们就要思考下一层:
第一,DeepSeek 是不是一定能解决 AGI 的所有工艺问题?
第二,DeepSeek 是不是只需一家之力就能实现终极 AGI?
第三,中国是不是只有 DeepSeek 一家有实力解决 AGI 的各个工艺问题?
同样以腾讯元宝为例。虽然元宝接入 DeepSeek 后可以赢得一时的胜利,但没有人能保证 DeepSeek 永远满分。如果有一天 DeepSeek 不开卷、竞争的规则被改写,又将攻守异位。
对于上述问题,笔者均持怀疑态度,原因很简单:DeepSeek 并非聚集了中国乃至全球所有的 AGI 工艺人才。即使曾经明星如云的 OpenAI,也因为2023、2024 年经历了大批核心人才出走,增长受阻。
关于 AGI,如果不将其当成只是 DeepSeek 一家的责任,而是作为整个 AI 行业的必然终局,那么就不难有一种朴素的感觉:AGI 的大航海,需要的不只是一个“DeepSeek”,也不会只有一个“DeepSeek”。AGI 是一个行业,而不是一个产物。
在 2 月的交流中,笔者总结,造成 AGI 从业者这种“既重视又低估”的矛盾心理的一个关键原因,或许是互联网思维的惯性。
经历过互联网大战的从业者向 AI 科技评论举例,“互联网产物就是竞争到最后往往就是只有一家胜出,比如出行大战、3Q 大战等等。”但笔者认为,这种类比不太恰当,因为互联网产物的工艺如搜推广从谷歌开始、再到国内时,大体的工艺天花板已经确定,而 DeepSeek 证明了 AGI 的天花板比 OpenAI 所取得的成绩还高。
与 AGI 或大模型能在同一个层面类比的工艺分支,或许用自动驾驶的 L4、英伟达芯片等高难度的工艺来类比更合适。虽然 L4 至今没有实现,但自动驾驶工艺从 L2 到 L4 的过程中曾衍生了不同维度的产物商业化(如扫地机器人),同样,AGI 也是一个逐步取得胜利、逐步催生商业工艺产物的过程。
有些团队本就不具备竞争 AGI 的工艺实力,但这并不能推断出“DeepSeek 是唯一能竞争 AGI 的创业团队”或“中国只需要一家 AGI 公司”的结论。哪怕是海外的各家基础模型,也在能力上各有分工,如 GPT 更擅长听指令、Claude 更擅长代码。
再回顾更大的行业规律:如果说搜广推工艺由谷歌开启、字节抖音推至巅峰,那么大模型工艺由 OpenAI 开启,由将由谁推至巅峰?互联网时代经历了 20 年才得出答案、中间也经历了许多故事,那么 AGI 时代也不可能只在 2 年内验证最初的赢家与最后的赢家。
那么,AGI 的壁垒在哪?
笔者认为,AGI 的壁垒实际是:运算规则的优势、工艺的创新虽然无法构成坚不可摧的壁垒,但可以赢得时间差。
以月之暗面为例。事实上,Moonshot 与 DeepSeek 都是在 2023 年的上半年成立、前后相差只有一个月。
在 2021 年智源的“悟道”大模型项目中,杨植麟也是悟道 2.0 大模型的核心开发者之一,从底层 Transformer 到上层大模型的运算规则训练都有完整、系统的研究背书。相比之下,DeepSeek 创始团队、包括梁文锋虽是计算机专业背景,但在 NLP、Transformer 与预训练等大模型的关键工艺上与 Moonshot 团队必然存在工艺学习的时间差。
如果以 Moonshot 在成立时就具备训练千亿大模型的能力开始算起,到 DeepSeek 在 2024 年 5 月发布 V2,那么这个时间差粗略计算大约是 1 年;如果严格考虑 V2 训练成本大幅降低的研发时间,这个时间差也至少是 6 个月以上。
但由于 Moonshot 在过去两年更重视产物增长、而非基础模型的底层工艺创新,Moonshot 与 DeepSeek 的基础模型时间差也从 2023 年“DeepSeek 至少比 Moonshot 落后半年”变成了 2025 年“Moonshot 至少比 DeepSeek 落后 XXX 年”。在互联网思维的过度指导下,前后相减,Moonshot 至少失去了一年的优势,主动变被动。
据知情人士透露,DeepSeek 内部计划今年 3 月发布 V3.5,6 月之前发布 V4。换言之,假设其他团队的基础模型能在 6 月赶上 V3 与 R1,作为先行者,DeepSeek 已经利用时间差赢得了领先的工艺研发期,以及这半年内的生态护城河。模型的效果容易提升,但生态不容易割据。
是坐享其成,还是参与竞争,亦或看清局势、早早转向自身的优势所在,不容易判断。尽管 DeepSeek 当前风头正盛,但 AGI 仍然是一个挂在高处的果子,需要持续的底层工艺创新。
在跋涉的过程中,一定会有人退出,无论是 VC 也好、创业者也好、工艺人员也好,但无论如何,这条路上不会只有 DeepSeek,也希望不会只有 DeepSeek。
雷峰网原创文章,未经授权禁止转载。详情见转载须知。


爱奇艺举办第五届“金豪笔编剧之夜” 62位编剧20部作品获表彰

“丹娜丝”进一步减弱 中央气象台对其停止编号
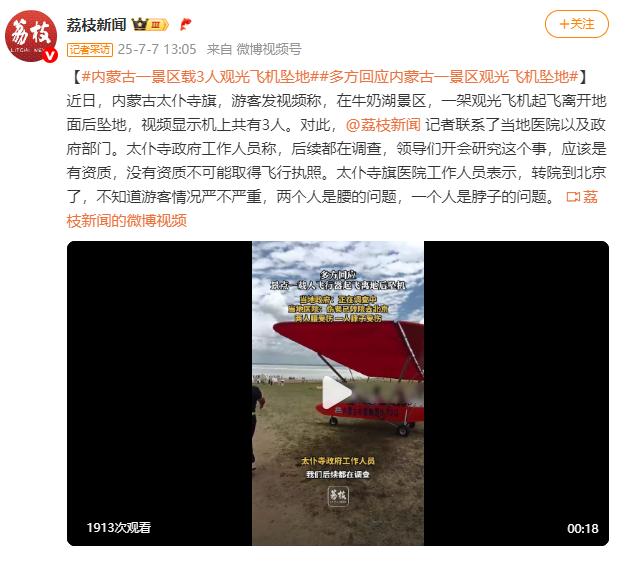
内蒙古一景区载3人观光飞机坠地,多方回应

4天7场演出,上海群文团队在3000米海拔牧场奏响“沪喀协奏曲”
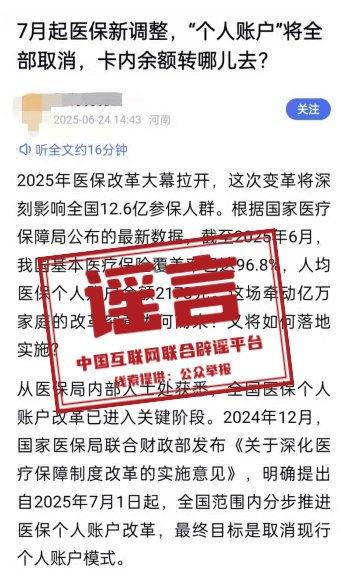
官方:“医保‘个人账户’将全部取消”系旧谣新传

抖音辟谣:“花费9位数与周杰伦签约”为谣言

美国洛杉矶一隧道坍塌 15人被困

盼盼×Hello Kitty限定包装登录永辉717好吃节,“萌趣”零食成为社交货币
Pieter Abbeel 新工作“大世界模型”:轻松玩转1小时长视频,一对一QA视频内容细节

男演员身份证照片引热议,证件照怎样拍才规范?

今年将举办50多场演唱会 鸟巢放歌引爆双奥场馆新热潮
4天7场演出,上海群文团队在3000米海拔牧场奏响“沪喀协奏曲”
 蓝振忠也发「英雄帖」,中国版 ChatGPT 明星公司寻找 CEO
蓝振忠也发「英雄帖」,中国版 ChatGPT 明星公司寻找 CEO蓝振忠也发「英雄帖」,中国版 ChatGPT 明星公司寻找 CEO
 多名事业单位在编人员被清退,牵出跨省作弊链
多名事业单位在编人员被清退,牵出跨省作弊链多名事业单位在编人员被清退,牵出跨省作弊链
 中方敦促也门胡塞武装维护红海水域航道保障
中方敦促也门胡塞武装维护红海水域航道保障中方敦促也门胡塞武装维护红海水域航道保障
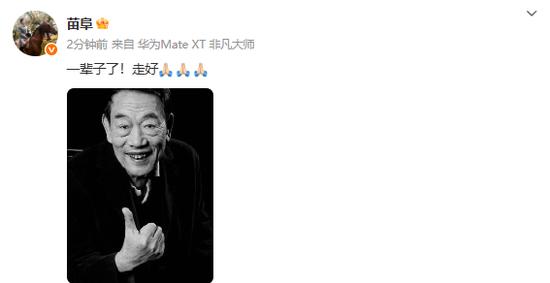 相声演员杨少华去世,曾登上春晚
相声演员杨少华去世,曾登上春晚相声演员杨少华去世,曾登上春晚
 百川智能首款 AI 应用主打懂搜索,但王小川不做搜索 2.0
百川智能首款 AI 应用主打懂搜索,但王小川不做搜索 2.0百川智能首款 AI 应用主打懂搜索,但王小川不做搜索 2.0
 古装传奇剧《藏海传》厚重底蕴精良制作引关注 不落爽剧窠臼 淬炼人性光辉
古装传奇剧《藏海传》厚重底蕴精良制作引关注 不落爽剧窠臼 淬炼人性光辉古装传奇剧《藏海传》厚重底蕴精良制作引关注 不落爽剧窠臼 淬炼人性光辉
 上半年我国汽车产销量均超1500万辆 新能源汽车表现亮眼
上半年我国汽车产销量均超1500万辆 新能源汽车表现亮眼上半年我国汽车产销量均超1500万辆 新能源汽车表现亮眼
 突发!俄罗斯发动大规模攻击
突发!俄罗斯发动大规模攻击突发!俄罗斯发动大规模攻击
 零一万物 API 上线,用户反馈多模态中文能力超过 GPT
零一万物 API 上线,用户反馈多模态中文能力超过 GPT零一万物 API 上线,用户反馈多模态中文能力超过 GPT
 日本首相石破茂:赌上国运战斗,不能被美国看扁
日本首相石破茂:赌上国运战斗,不能被美国看扁日本首相石破茂:赌上国运战斗,不能被美国看扁
官方:“医保‘个人账户’将全部取消”系旧谣新传官方:“医保‘个人账户’将全部取消”系旧谣新传
 国务院任免国家工作人员
国务院任免国家工作人员国务院任免国家工作人员













